Architecture Note - REALM
REALM: Read Edit/Analyze Loop Monitor
February 1, 2026
Estimated read: 6 min
REALM is a Read Edit/Analyze Loop Monitor architecture for turning large documents into the smallest useful context for downstream systems. It leans on how text models are trained to navigate structured documents and books, then applies a modular REPL-like loop to keep token cost low while preserving semantic signal.
REALM stands for Read Edit/Analyze Loop Monitor.
The core idea is simple: most instruction corpora are still document-shaped. Books, manuals, API docs, and policy guides are naturally split into sections and subsections. Models are typically trained on this structure, so they can often recover meaning better from a guided section path than from one giant flat prompt.
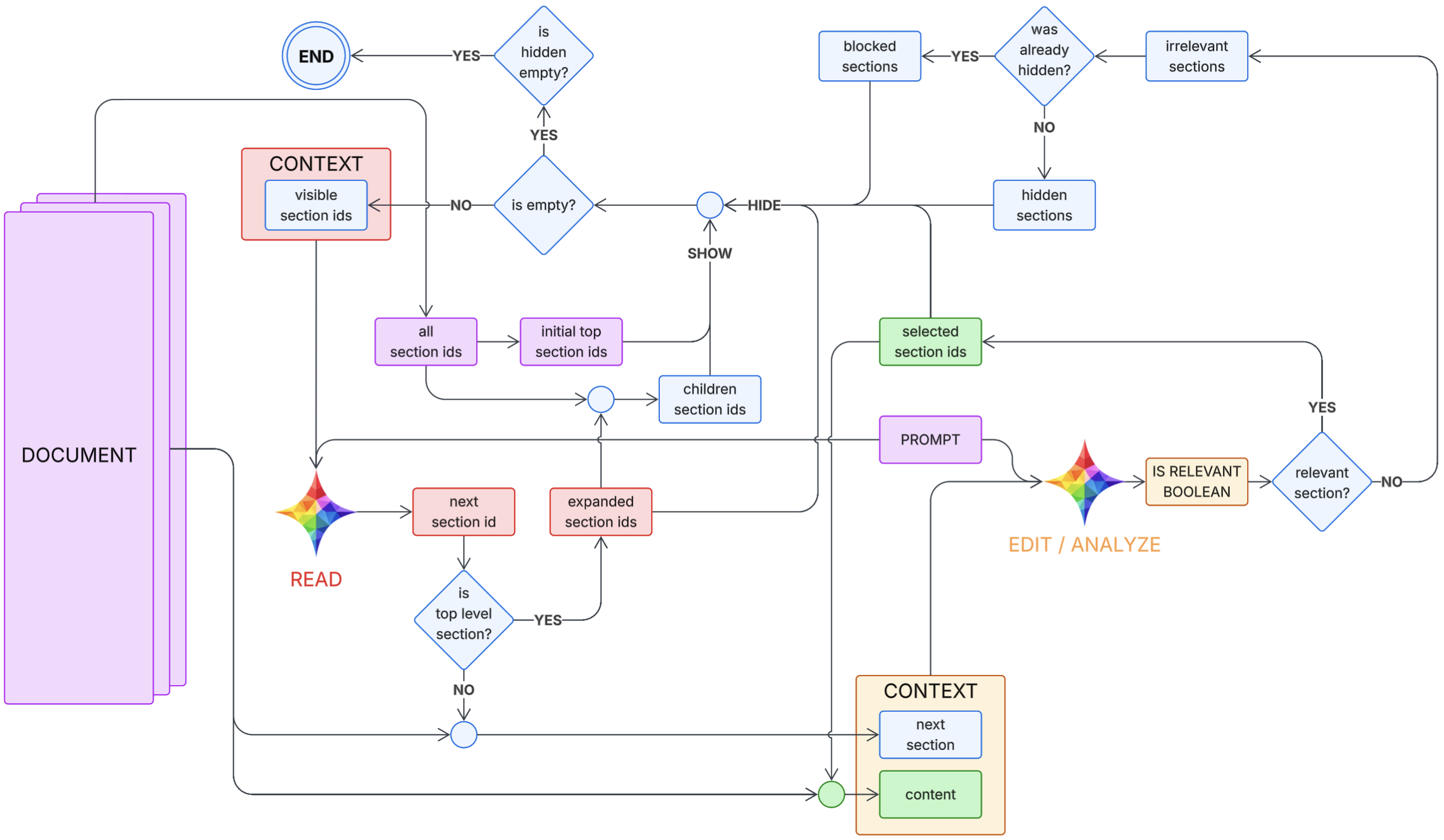
Why REALM Exists
When a system needs to follow a large ruleset, there are two common failure modes:
- Full-text prompting gets expensive quickly.
- One-shot retrieval misses nuance hidden in neighboring sections.
REALM is an attempt to keep both cost and error risk bounded by curating only what is needed for the current task.
Architecture Overview
REALM Components
| Component | Primary job | Compute profile |
|---|---|---|
| Reader | Select next section candidates from the document structure | Small model / on-device |
| Editor/Analyzer | Summarize and normalize selected text into task-ready context | Small to medium model |
| Loop Controller | Track state, stop conditions, and budget limits | Rule-based + lightweight model |
| Monitor | Validate context quality and trigger recovery if needed | Stronger model, called less often |
| Worker System | Execute the task using curated context | Tool runner or task model |
REPL-Style Loop
I think of REALM as a REPL for context curation:
state = init(task, rules_doc)
budget = token_budget(max_input, max_output, max_iters)
while not state.done and budget.remaining > 0:
next_section = Reader.pick(state.query, state.available_sections, state.history)
draft = EditorAnalyze.extract(next_section, state.query, state.constraints)
state.context = merge(state.context, draft)
verdict = Monitor.check(state.context, state.query, quality_bar)
if verdict == "sufficient":
state.done = true
elif verdict == "off-path":
state = recover(state, verdict)
emit(state.context)
This design keeps each step narrow. Instead of asking for everything at once, REALM grows context in controlled increments and stops as soon as quality is good enough.
Why Section Structure Matters
Document boundaries are useful semantic hints. A section title, nearby headers, and local paragraph context often carry stronger signal than isolated sentence chunks. REALM uses that structure directly, so the loop can:
- Preserve meaning around rules and exceptions.
- Avoid overloading each call with unrelated content.
- Keep per-iteration context windows small and predictable.
Monitor + Worker Split
REALM separates two concerns:
- Curate context cheaply (Reader + Editor/Analyzer loop).
- Use context for execution (Worker system).
A stronger monitoring model can be called strategically to validate quality, while the curation loop itself stays lightweight. That lets you reserve higher-cost reasoning for checkpoints instead of every iteration.
Skill and Tool Selection Potential
Because REALM produces structured, task-scoped context, it can also help with routing:
- Select which skill should run next.
- Choose tools with the right constraints already attached.
- Pass only the minimum relevant rules to the execution layer.
This can reduce brittle tool calls that happen when models see too much irrelevant policy text.
On-Device Path
The long-term value is modularity. If each loop step is small enough, portions of REALM can run with smaller models, including on-device scenarios without a GPU. That makes it plausible to keep sensitive rule processing local while still using stronger remote models only when the monitor decides it is necessary.
Practical Goal
REALM is not trying to make big models unnecessary. The goal is to make context curation cheap, auditable, and reusable so downstream systems can do better work with less input noise and lower token cost.