First Log - REALM Experiments
Context Curation: Preliminary REALM Tests
February 3, 2026
Estimated read: 5 min
This log evaluates a core hypothesis: an agent should be able to navigate a document by reading a table of contents in small steps, instead of loading the full text into every prompt. I tested a minimal read loop across multiple document sizes and two queries. In these runs, both cloud models reached the correct section within two iterations across all sizes. That is the baseline signal needed before expanding toward the broader REALM loop for production context curation.
- Run 1:
gpt-4o-mini- February 3, 2026 - 04:33:52 UTC - Run 2:
gpt-5-nano- February 3, 2026 - 04:40:19 UTC - Scope: read loop only (navigate + accumulate context)
- Queries: Authentication and rate limiting
- Max iterations: 5
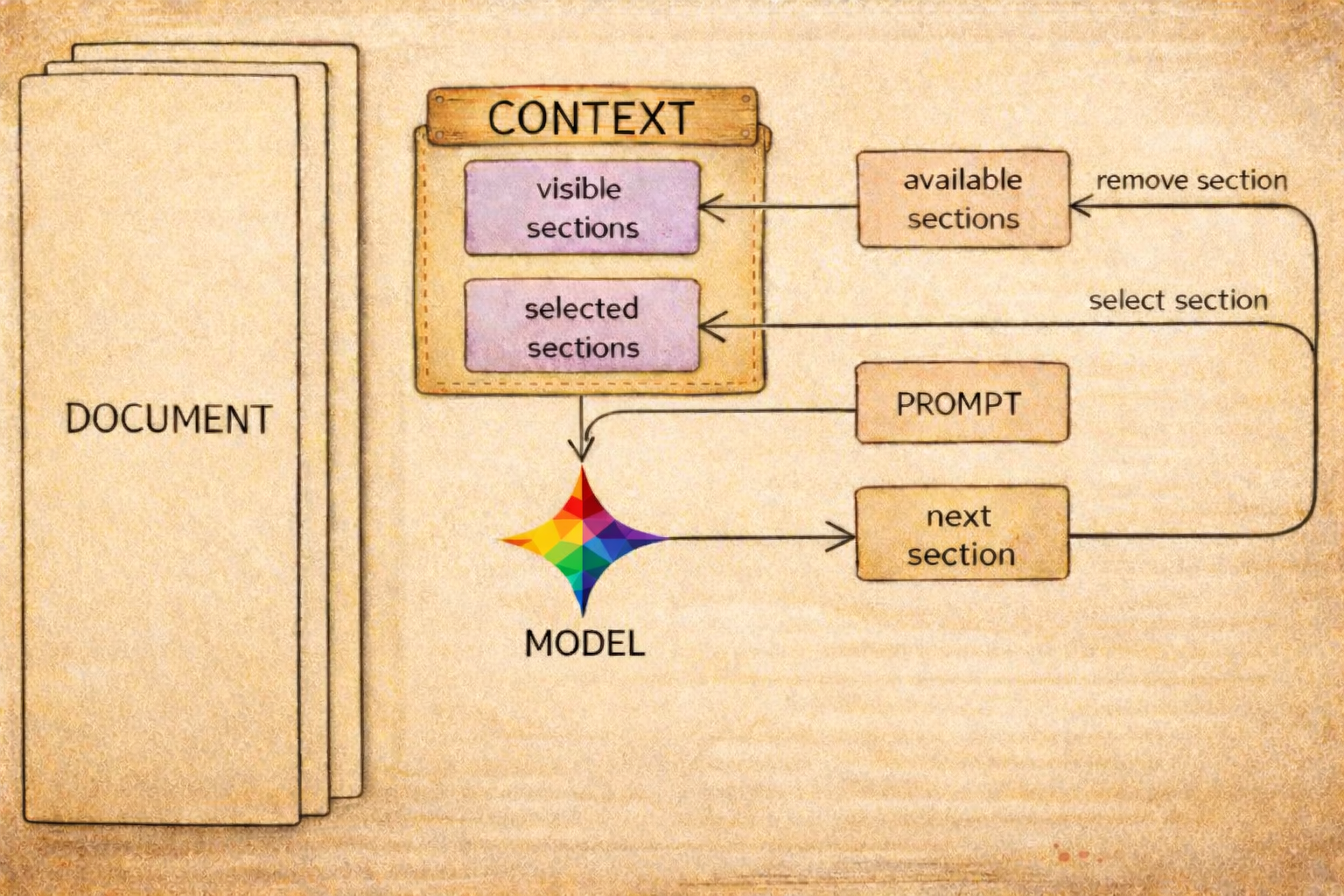
REALM as Context Curation
This post treats REALM as a context curation system. The model does not receive the full document up front. Instead, it progressively pulls in only the sections that appear relevant to the current question. The mechanism is intentionally simple: a table of contents, a constrained list of candidate next sections, and a loop that appends selected sections into the working context.
This matters because common alternatives do not scale cleanly. Full-text prompting scales linearly with content size. Embedding-based retrieval can flatten or ignore the hierarchy that documentation already provides. Manual curation does not scale when both content volume and query volume increase. REALM attempts to preserve document structure while keeping per-call context bounded.
This first log focuses on navigation accuracy and context growth. The next phase is to expand toward the full loop and its operational pitfalls, including stop conditions, confidence estimation, guardrails, and richer tool and document graphs.
What I Tested
I compared two approaches across five document sizes (9 to 260 sections) and two queries, with a maximum of 5 iterations.
- Iterative REALM: select a section, read it, and repeat until the relevant section is located
- Full-text: attempt a one-shot selection from the entire document
Queries Used
How do I authenticate API requests?What are the rate limits?
Results: multi-size-experiment-2026-02-03.json
Data sources:
Basic Loop
available_sections = toc(document)
selected_sections = []
for iteration in 1..5:
prompt = build_prompt(query, available_sections, selected_sections)
next_section = llm_select(prompt)
selected_sections.append(next_section)
available_sections.remove(next_section)
if has_answer(selected_sections, query):
# early-stop candidate
record(iteration, selected_sections)
The focus of this post is the selection step. Can the model consistently choose a useful next section from a constrained menu, and continue doing so as the document grows?
Result Snapshot
gpt-4o-mini Token Usage by Doc Size
Average tokensTotal across both queries.
-
Small
Iterative --Full-text --
-
Medium
Iterative --Full-text --
-
XLarge
Iterative --Full-text --
-
XXLarge
Iterative --Full-text --
-
XXXLarge
Iterative --Full-text --
gpt-5-nano Token Usage by Doc Size
Average tokensTotal across both queries.
-
Small
Iterative --Full-text --
-
Medium
Iterative --Full-text --
-
XLarge
Iterative --Full-text --
-
XXLarge
Iterative --Full-text --
-
XXXLarge
Iterative --Full-text --
What This Suggests
- Both approaches scale with document size: totals increase predictably from Small to XXXLarge.
- gpt-4o-mini converges: iterative and full-text totals become similar at larger sizes.
- gpt-5-nano shows a larger gap: iterative remains higher than full-text on total tokens under a fixed 5-iteration budget.
Full-Text Is a Fragile Interface
Full-text prompting appears simpler, but its failure mode is difficult to manage operationally. The model must scan thousands of tokens, select one section, and return it in a strict format. In practice, it can select an irrelevant section, return an invalid identifier, or produce a plausible answer that is not grounded in the document. Because the call is single-shot, there is no built-in recovery step.
Reliability Comparison
| Aspect | Full-Text | Iterative (REALM) |
|---|---|---|
| Task complexity | Scan the entire document and select one section in a single step | Select from a constrained menu at each step |
| Error recovery | None. Single-shot selection | Iterative correction across steps |
| Failure predictability | Harder to anticipate across documents and queries | More predictable because each step is constrained |
| Fix difficulty | Harder. Prompt tuning has diminishing returns at scale | Easier. Improvements are mostly constraint clarity and validation |
| Production posture | Higher operational risk | More reliable through bounded steps and graceful degradation |
Current view: iterative selection tends to be more operationally reliable, even when it is not always the lowest-token option for very small documents.
Early Stopping Is the Biggest Multiplier
The clearest signal is not the 5-iteration total. It is the iteration at which the loop first reaches the correct section. If the loop stops as soon as it has enough evidence to answer, token usage can drop substantially. To keep the comparison aligned with the earlier charts, the view below compares one-shot full-text against stop-at-first-correct, averaged across both queries.
gpt-4o-mini Early Stopping Savings by Doc Size
Average full-text tokensTotal vs average tokensToCorrect across both queries.
-
Small
Full-text --Stop @ first correct --
--
-
Medium
Full-text --Stop @ first correct --
--
-
XLarge
Full-text --Stop @ first correct --
--
-
XXLarge
Full-text --Stop @ first correct --
--
-
XXXLarge
Full-text --Stop @ first correct --
--
gpt-5-nano Early Stopping Savings by Doc Size
Average full-text tokensTotal vs average tokensToCorrect across both queries.
-
Small
Full-text --Stop @ first correct --
--
-
Medium
Full-text --Stop @ first correct --
--
-
XLarge
Full-text --Stop @ first correct --
--
-
XXLarge
Full-text --Stop @ first correct --
--
-
XXXLarge
Full-text --Stop @ first correct --
--
What This Suggests
- Small documents can still favor full-text: one-shot can be cheaper at the smallest input sizes.
- As documents grow, early stopping tends to win: stop-at-first-correct reduces token usage sharply for larger inputs.
- Early stopping is architectural: it should be a first-class control, not an optional optimization.
Per-Iteration Growth Stays Manageable
Context grows each iteration because selected sections accumulate. In a representative medium run, growth remained controlled while output tokens stayed small, since the model was not producing long explanations during selection.
This is promising for smaller local models. Keeping each call bounded to a much smaller context window can make the loop more practical on constrained hardware, especially when stop conditions keep the number of iterations low.
Per-Iteration Token Growth (Medium, Auth Query, gpt-4o-mini)
| Iter | Input | Output | Total | Cumulative |
|---|---|---|---|---|
| 1 | 816 | 12 | 828 | 828 |
| 2 | 1,018 | 7 | 1,025 | 1,853 |
| 3 | 1,068 | 9 | 1,077 | 2,930 |
| 4 | 1,179 | 9 | 1,188 | 4,118 |
| 5 | 1,336 | 7 | 1,343 | 5,461 |
Input grows as selected sections accumulate, but each step remains within a narrow band. That makes the loop easier to reason about and budget.
Per-Call Context Windows Stay Small
Max Single-Iteration Input (gpt-4o-mini)
| Document Size | Full-Text Input | REALM Max Single Iteration | Reduction |
|---|---|---|---|
| Small (9 sections) | 443 | 398 | 10% |
| Medium (78 sections) | 5,288 | 1,336 | 75% |
| XLarge (124 sections) | 8,878 | 1,804 | 80% |
| XXLarge (195 sections) | 12,052 | 2,538 | 79% |
| XXXLarge (260 sections) | 15,081 | 3,245 | 78% |
This is the practical value of the loop. It converts a large-document problem into a sequence of smaller, bounded calls.
Takeaways from This First Pass
- The baseline loop is viable. Iterative section selection remains stable as content grows.
- For
gpt-4o-mini, iterative becomes token-competitive around 30 KB documents and remains competitive beyond that. - Full-text selection is operationally fragile because it provides no recovery path when it selects the wrong section.
- Early stopping should be a first-class control. In these runs, it typically reduced a 5-iteration budget to about 2 iterations.
- Next step: evaluate a local small language model on the same loop, then extend toward the full REALM design with explicit stop criteria, confidence signals, and validation.