Second Log - REALM Experiments
REALM Continuation: Local SLM Evaluation with gemma3:1b
February 4, 2026
Estimated read: 6 min
This continuation tests whether a local 1B model can run the same REALM read loop effectively on larger documentation. The core result is strong: on Medium through XXXLarge documents, gemma3:1b uses fewer tokens than full-text prompting while keeping per-iteration context windows small enough for constrained hardware.
- Continuation of: Context Curation: Preliminary REALM Tests
- Run:
gemma3:1blocal SLM (Ollama), executed February 3, 2026 and finalized in this write-up on February 4, 2026 - Scope: same read-loop benchmark shape as 02-03, focused on Medium to XXXLarge documents
- Queries: authentication and rate-limiting
- Max iterations: 5
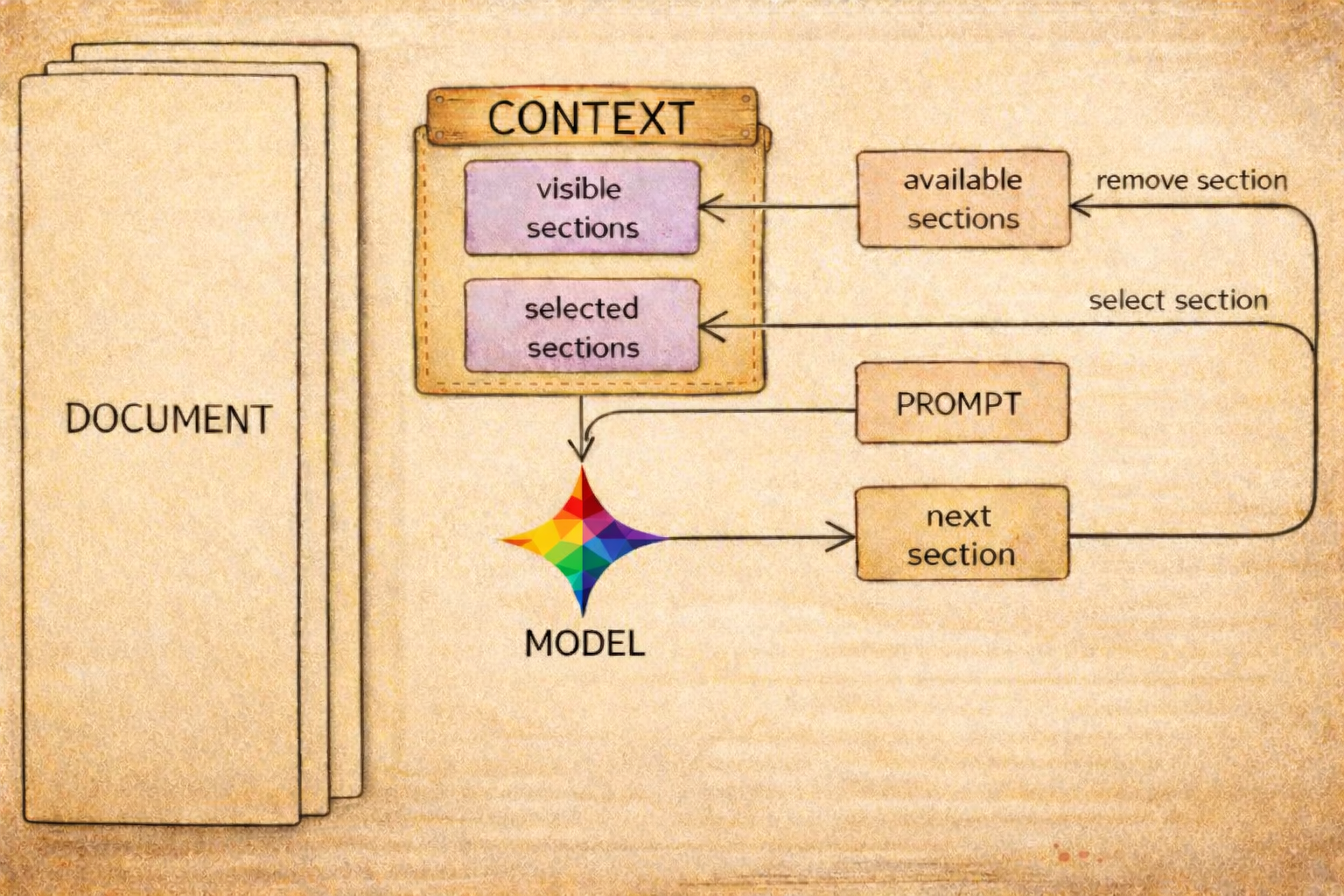
Why This Follow-up
The 02-03 post established that the loop mechanics work on cloud models. This continuation asks a narrower question: can a very small local model run the same loop in a useful way for larger documents?
The answer from this first pass is yes for Medium through XXXLarge. On those sizes, gemma3:1b is consistently cheaper than full-text in token terms, and still follows the same constrained section-navigation pattern.
Data for This Run
Results and extracted chart payload:
multi-size-experiment-2026-02-04-gemma3-1b.json- Baseline reference:
multi-size-experiment-2026-02-03.json
gemma3:1b vs Full-Text (Same Loop Setup)
gemma3:1b Token Usage by Document Size
| Document | Size | Sections | Iterative Avg Tokens | Full-Text Avg Tokens | Difference |
|---|---|---|---|---|---|
| Medium | 18.1KB | 78 | 4,260 | 5,364 | -1,104 (-20.6%) |
| XLarge | 30.1KB | 124 | 5,793 | 8,800 | -3,008 (-34.2%) |
| XXLarge | 41.6KB | 195 | 8,214 | 12,327 | -4,113 (-33.4%) |
| XXXLarge | 52.6KB | 260 | 10,524 | 15,679 | -5,155 (-32.9%) |
Average across both queries. Negative difference means iterative used fewer tokens than full-text.
gemma3:1b Token Usage by Doc Size
Average tokensTotal across both queries.
-
Medium
Full-text --Iterative --
-
XLarge
Full-text --Iterative --
-
XXLarge
Full-text --Iterative --
-
XXXLarge
Full-text --Iterative --
gemma3:1b Early Stopping Savings
Average full-text tokensTotal vs average tokensToCorrect.
-
Medium
Full-text --Early Stop --
--
-
XLarge
Full-text --Early Stop --
--
-
XXLarge
Full-text --Early Stop --
--
-
XXXLarge
Full-text --Early Stop --
--
Comparison with the 02-03 Models
Iterative Tokens: Local SLM vs Prior Cloud Runs
| Document | gemma3:1b Iterative | gpt-4o-mini Iterative | gpt-5-nano Iterative | gemma3:1b Position |
|---|---|---|---|---|
| Medium | 4,260 | 5,326 | 8,874 | 20% lower than gpt-4o-mini; 52% lower than gpt-5-nano |
| XLarge | 5,793 | 7,654 | 12,255 | 24% lower than gpt-4o-mini; 53% lower than gpt-5-nano |
| XXLarge | 8,214 | 11,275 | 15,613 | 27% lower than gpt-4o-mini; 47% lower than gpt-5-nano |
| XXXLarge | 10,524 | 14,742 | 20,515 | 29% lower than gpt-4o-mini; 49% lower than gpt-5-nano |
Cross-model view uses average iterative tokens across both queries on the shared size range (Medium to XXXLarge).
Model-Level Efficiency on Shared Sizes
| Model | Iterative Avg Tokens | Full-Text Avg Tokens | Iterative - Full-Text |
|---|---|---|---|
| gpt-4o-mini | 9,749 | 10,327 | -578 (-5.6%) |
| gpt-5-nano | 14,314 | 10,646 | +3,668 (+34.5%) |
| gemma3:1b | 7,198 | 10,542 | -3,344 (-31.7%) |
Model-level averages across Medium to XXXLarge only.
This does not claim that gemma3:1b is stronger overall than the larger cloud models. It does show that, within this constrained navigation task, a 1B local model can be operationally useful and token-competitive when paired with the REALM loop design.
Convergence Behavior
First-Correct and Early-Stop Comparison
| Model | Avg First Correct Iteration | Avg Tokens to Correct | Observation |
|---|---|---|---|
| gpt-4o-mini | 2.00 | 3,592 | Stable and early across sizes in this range |
| gpt-5-nano | 2.00 | 4,719 | Early convergence with higher token overhead |
| gemma3:1b | 2.75 | 3,921 | Fast on auth; slower on rate-limit queries at larger sizes |
Averages computed from iterative runs with available first-correct markers.
Two patterns stand out:
gemma3:1bis very strong on the authentication query (first correct at iteration 2 across sizes).- It takes longer on the rate-limiting query at larger sizes (first correct at iteration 4), which lowers early-stop savings there.
Per-Call Context Remains Small
Per-Call Context Window (gemma3:1b)
| Document | Full-Text Input | gemma3:1b Max Single Iteration Input | Reduction |
|---|---|---|---|
| Medium | 5,363 | 931 | 83% |
| XLarge | 8,796 | 1,237 | 86% |
| XXLarge | 12,318 | 1,729 | 86% |
| XXXLarge | 15,672 | 2,199 | 86% |
Per-call context stays substantially smaller than full-text, which is the key SLM usability signal.
This is the important SLM signal. The loop keeps each call bounded, which makes CPU-local inference more practical than repeatedly sending the full document.
Representative Iteration Growth
Per-Iteration Token Growth (Medium, Auth Query, gemma3:1b)
| Iter | Input | Output | Total | Cumulative |
|---|---|---|---|---|
| 1 | 622 | 53 | 675 | 675 |
| 2 | 789 | 36 | 825 | 1,500 |
| 3 | 825 | 41 | 866 | 2,366 |
| 4 | 899 | 39 | 938 | 3,304 |
| 5 | 931 | 41 | 972 | 4,276 |
Representative run: Medium document, auth query, gemma3:1b iterative. First correct section appears at iteration 2.
Known Failure Mode in This Pass
The Small document case (9 sections) was excluded from this JSON run because iterative selection failed with invalid section IDs (for example "1.2"). The issue appears to be prompt/schema clarity for tiny local models, not a loop design issue.
Full-Text Reliability in This Local SLM Run
| Document | Full-Text Attempts | Incorrect Selections | Example Full-Text Output |
|---|---|---|---|
| Medium | 2 | 2 | 3 |
| XLarge | 2 | 2 | --- Section: 1 --- |
| XXLarge | 2 | 2 | --- Section: initialization --- |
| XXXLarge | 2 | 2 | --- Section: data-sources |
In this local SLM run set, full-text responses were incorrect for all eight attempts.
Next Steps from This SLM Pass
- Tighten section-ID constraints in the prompt (explicit allowed IDs + exact-match requirement).
- A/B test prompt variants on Small documents to recover reliability.
- Move to next loop component: Editor/Analyzer. Can the local SLM not only pick sections but also extract and summarize them effectively for downstream use?