Third Log - REALM Experiments
REALM Combined Loop: Multi-Size Results Toward Context Compiler
February 21, 2026
Estimated read: 7 min
This run moves past read-only section selection and uses the combined Read + Edit/Analyze loop. Across Medium through XXXLarge documents, the loop keeps iterative totals near ~1k tokens while full-text grows from ~5.6k to ~17.3k, which is a strong operational signal for context compiler workflows.
- Builds on: REALM: Read Edit/Analyze Loop Monitor
- Follow-up to experiments: Context Curation: Preliminary REALM Tests and REALM Continuation: Local SLM Evaluation with gemma3:1b
- Context compiler direction: Context Compiling: ctxc and vectorless builds
- Run:
gemma3:1b, executed on February 21, 2026 (2026-02-21T05:34:30Z) - Scope: combined Read + Edit/Analyze loop across 5 document sizes
- Max iterations: 5
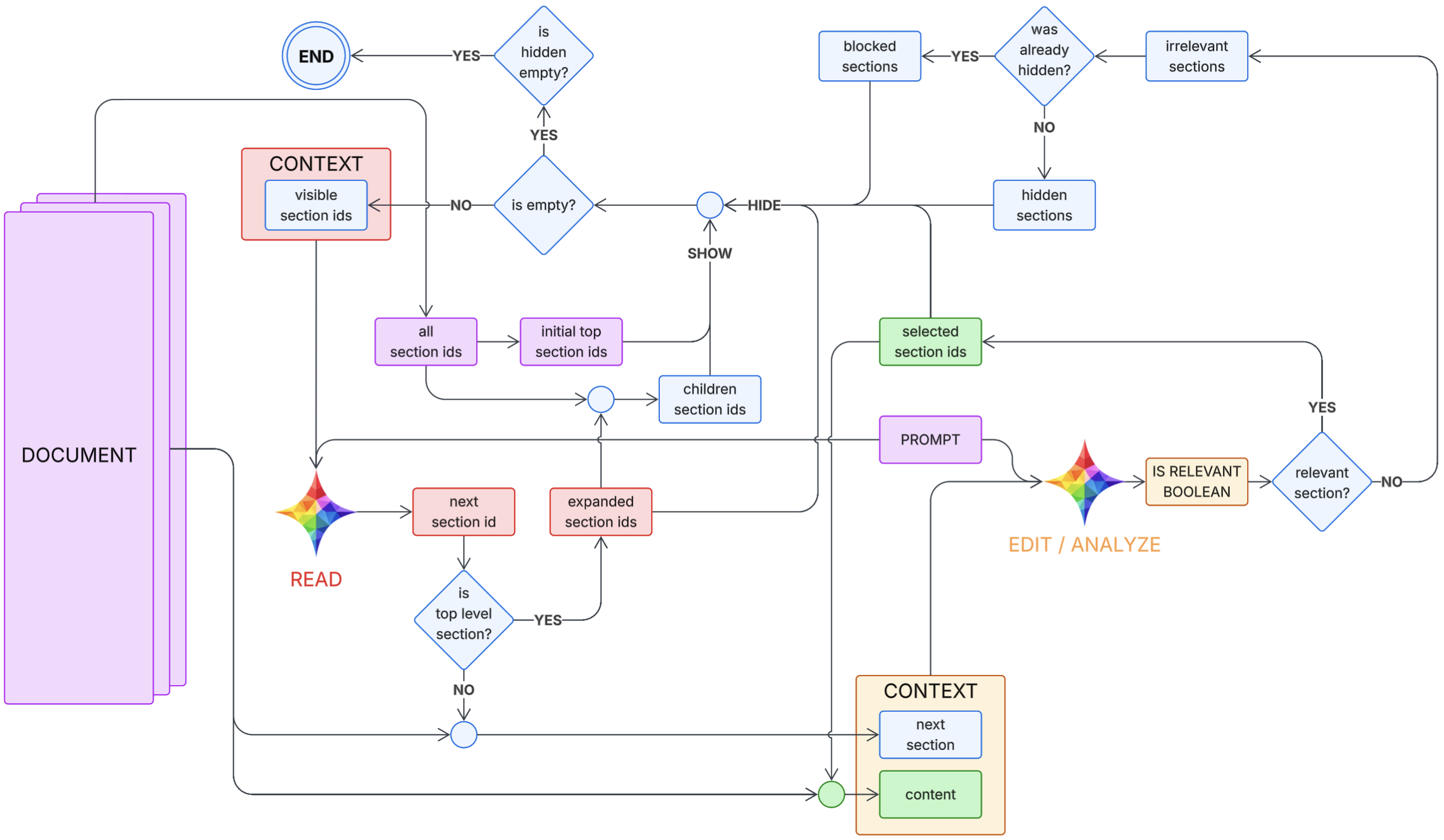
Why This Run Matters
The 02-03 and 02-04 posts validated section navigation. This run moves one step closer to ctxc: it combines section selection with relevance analysis in the same loop so the system is already curating task-ready context while navigating.
The key signal is stability under growth. Across Medium through XXXLarge, iterative totals stay near ~1k tokens while full-text scales to 5k to 17k+.
Data for This Run
Primary JSON dataset copied into this repo:
Comparison reference:
Combined Loop vs Full-Text
Token Usage by Document Size (Combined Loop)
| Document | Size | Sections | Iterative Avg Tokens | Full-Text Avg Tokens | Difference |
|---|---|---|---|---|---|
| Small | 1.2KB | 9 | 707 | 495 | +212 (+42.7%) |
| Medium | 18.1KB | 78 | 992 | 5,586 | -4,595 (-82.3%) |
| XLarge | 30.1KB | 124 | 1,030 | 9,387 | -8,357 (-89.0%) |
| XXLarge | 41.6KB | 195 | 1,110 | 13,468 | -12,358 (-91.8%) |
| XXXLarge | 52.6KB | 260 | 1,194 | 17,275 | -16,082 (-93.1%) |
Averages across both queries. Negative difference means iterative used fewer tokens than full-text.
Small is still the edge case where one-shot full-text can be cheaper. After that, the combined loop dominates in token efficiency.
Comparison with the 02-04 gemma3:1b Run
Iterative Token Comparison on Shared Sizes
| Document | 02-04 Iterative (Read Loop) | 02-21 Iterative (Read + Edit/Analyze) | Difference |
|---|---|---|---|
| Medium | 4,260 | 992 | -3,268 (-76.7%) |
| XLarge | 5,793 | 1,030 | -4,763 (-82.2%) |
| XXLarge | 8,214 | 1,110 | -7,104 (-86.5%) |
| XXXLarge | 10,524 | 1,194 | -9,330 (-88.7%) |
Directional comparison to the 02-04 post on shared sizes. Not a strict apples-to-apples benchmark because prompts and loop internals changed.
This is the practical trend I care about for context compiling: tighter, more stable token ceilings per run as document size increases.
Convergence and Early Stop Potential
Authentication Query: First-Correct and Savings
| Document | First Correct | Tokens to Correct | Total Tokens | Potential Savings |
|---|---|---|---|---|
| Small | 2 | 271 | 732 | 461 (63.0%) |
| Medium | 2 | 343 | 1,013 | 670 (66.1%) |
| XLarge | 3 | 575 | 1,070 | 495 (46.3%) |
| XXLarge | 2 | 368 | 1,149 | 781 (68.0%) |
| XXXLarge | 2 | 390 | 1,232 | 842 (68.3%) |
Authentication query early-stop behavior.
Rate-Limiting Query: First-Correct and Savings
| Document | First Correct | Tokens to Correct | Total Tokens | Potential Savings |
|---|---|---|---|---|
| Small | N/A | 0 | 681 | 681 (N/A) |
| Medium | 2 | 336 | 970 | 634 (65.4%) |
| XLarge | 2 | 341 | 989 | 648 (65.5%) |
| XXLarge | 2 | 362 | 1,071 | 709 (66.2%) |
| XXXLarge | 2 | 383 | 1,155 | 772 (66.8%) |
Rate-limiting query early-stop behavior. Small did not reach first-correct in this run.
On Medium through XXXLarge, first-correct appears at iteration 2 in 7 of 8 runs. That is strong evidence that stop-at-sufficient can be a first-class optimization in the compiler loop.
Full-Text Reliability in This Run
Full-Text Selection Accuracy
| Document | Full-Text Attempts | Correct | Accuracy |
|---|---|---|---|
| Small | 2 | 0 / 2 | 0% |
| Medium | 2 | 0 / 2 | 0% |
| XLarge | 2 | 0 / 2 | 0% |
| XXLarge | 2 | 2 / 2 | 100% |
| XXXLarge | 2 | 0 / 2 | 0% |
Full-text selected incorrect section IDs on 8 of 10 attempts.
The full-text path still has a brittle interface here: most failures are wrong or malformed section selections.
Per-Call Context Boundaries
Per-Call Context Window
| Document | Avg Full-Text Input | Max Single Iteration Input | Reduction |
|---|---|---|---|
| Small | 489 | 149 | 70% |
| Medium | 5,585 | 228 | 96% |
| XLarge | 9,382 | 239 | 97% |
| XXLarge | 13,445 | 261 | 98% |
| XXXLarge | 17,259 | 282 | 98% |
Single-call context remains bounded even as full documents grow.
Representative Iteration Growth
Per-Iteration Token Growth (XXXLarge, Rate-Limit Query)
| Iter | Input | Output | Total | Cumulative |
|---|---|---|---|---|
| 1 | 124 | 14 | 138 | 138 |
| 2 | 237 | 8 | 245 | 383 |
| 3 | 255 | 12 | 267 | 650 |
| 4 | 247 | 10 | 257 | 907 |
| 5 | 241 | 7 | 248 | 1,155 |
Representative run: XXXLarge, rate-limit query, combined loop.
Loop Sketch Used for This Architecture
This is the same pseudocode model introduced in the 02-01 architecture post, which is the basis for this combined-loop run.
def run(prompt, doc):
# Document API assumptions:
# - doc.top_level_ids() -> list[str]
# - doc.children_ids(section_id) -> list[str]
# - doc.read_content(section_id) -> str
# - doc.read_all_content(section_ids) -> str
visible = set(doc.top_level_ids()) # "visible section ids"
expanded = set() # prevents re-expanding the same parent
hidden = set() # hidden once (eligible for second look)
blocked = set() # hidden twice (final exclude)
selected = set() # OUTPUT: relevant ids
visited = set() # loop protection
while True:
# Termination / resurfacing
if not visible:
if not hidden:
break # END
# SHOW: resurface hidden candidates for a second pass
visible |= (hidden - blocked)
# READ model chooses next id using only (prompt, visible)
next_id = READ(prompt, visible)
# Loop protection: if we ever revisit an id, exit (architecture invariant broken)
if next_id in visited:
break # or raise RuntimeError(f"READ returned already visited id: {next_id}")
visited.add(next_id)
# Defensive: if READ returns something not visible, drop it and continue
if next_id not in visible:
continue
# Consume this choice so READ cannot pick it again immediately
visible.remove(next_id)
# Expand if it has children (do not run EDIT/ANALYZE on non-leaf)
children = doc.children_ids(next_id)
if children:
if next_id not in expanded:
expanded.add(next_id)
# SHOW children, but do not re-add anything already hidden/blocked/selected
visible |= (set(children) - hidden - blocked - selected)
continue
# Leaf section: run EDIT/ANALYZE
next_content = doc.read_content(next_id)
content = doc.read_all_content(selected) # all selected content so far
is_relevant = EDIT_ANALYZE(prompt, next_content, content)
if is_relevant:
selected.add(next_id)
hidden.remove(next_id) # if it had been hidden before, clear it
continue
# Irrelevant leaf: HIDE / BLOCK logic
if next_id in hidden:
# Second strike -> BLOCK, and remove from hidden as requested
hidden.remove(next_id)
blocked.add(next_id)
else:
# First strike -> HIDE
hidden.add(next_id)
content = doc.read_all_content(selected) # all selected content so far
is_done = MONITOR(prompt, content)
if is_done:
break
return selected
What This Suggests for ctxc
- The combined loop can keep context compilation bounded even as source docs scale.
- First-correct behavior is early enough to support aggressive stop conditions.
- The remaining weak spot is strict section-ID output reliability in one-shot full-text mode, not the loop structure itself.
For broader context, this should be read alongside 02-01 architecture, 02-03 baseline experiments, 02-04 local SLM continuation, and 02-18 ctxc direction.